
![]()
Welcome to our presentation repo, where you’ll find extra info on the topics we’ve presented. This is meant to give you a more in-depth look at the material, with additional examples, contexts, and more.
If you are looking for technical documentation for aruna itself please click here.
A rendered version of this repo can be found here:
Developer info
Deploy Locally with Docker for Testing
- In the repository’s root directory, run
docker run -v $PWD:/book -p 3000:3000 peaceiris/mdbook serve --hostname 0.0.0.0 - Browse to http://localhost:3000
- You can edit the content while the container is running and see the results immediately.
Contributing
The contribution to the wiki is done via pull requests. The book is rendered as markdown via the src directory.
SUMMARY.md contains the table of content for the book.
License
This work is licensed under a Creative Commons Attribution-NoDerivs 4.0 International License.

KubeCon + CloudNativeCon NA 2024
Poster: Accepting mortality: Strategies for ultra-long running stateful workloads in K8s
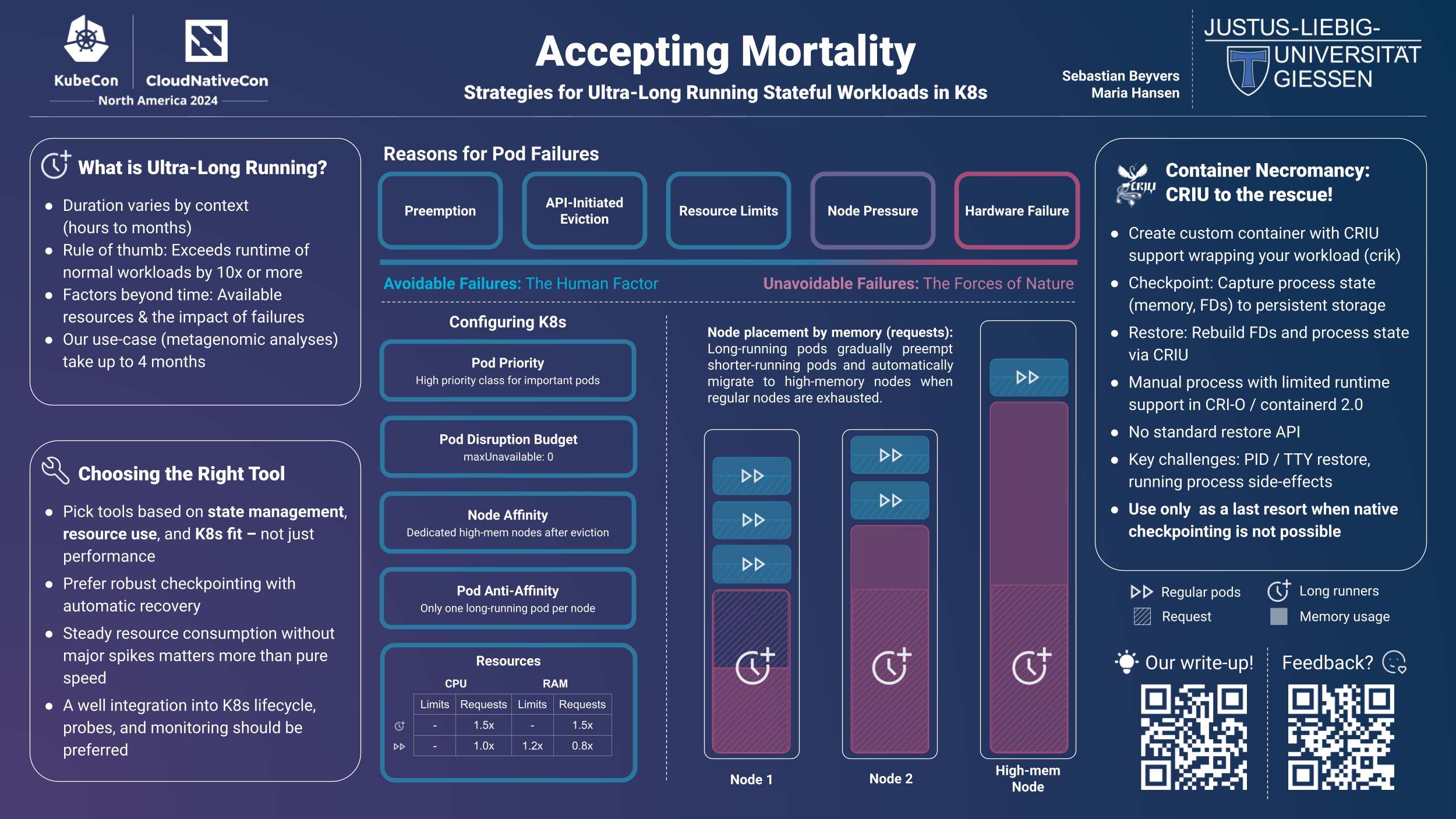
Table of Contents
- Introduction
- What Makes a Workload “Ultra-Long Running”?
- Understanding Pod Mortality: The Inevitable and the Preventable
- Strategies for Success
- Summary and Outlook
Introduction
“Pods are mortal” - this frequently cited credo from the Kubernetes documentation has long been used to argue against running stateful workloads on Kubernetes. The ephemeral nature of Pods, while perfect for resilient microservices, was supposedly unsuitable for workloads that required persistence and long-term stability.
But times have changed. Kubernetes has come a long way since it first started out focusing on stateless applications. These days, it’s not just possible to run databases and other stateful workloads on Kubernetes – it’s becoming the norm. Thanks to redundant setups and reliable persistent volumes, the “mortality” of Pods has gone from a limitation to a manageable design consideration.
This change hasn’t just affected traditional stateful services. In recent years, Kubernetes has emerged as a great alternative to traditional high-performance and high-throughput computing environments. Tools like Argo Workflows and Apache Airflow make it really easy to orchestrate compute jobs on Kubernetes. For many computational tasks, Pod mortality is not a problem. If a job fails, it can simply be rescheduled.
However, a new challenge has emerged as organisations move legacy applications and intensive computations from traditional HPC systems to Kubernetes. These workloads, which we call “ultra-long running”, can run for days or even weeks. At these timescales, the implications of Pod mortality become much more severe, raising important questions about how we design for reliability at the extreme end of the runtime spectrum.
What Makes a Workload “Ultra-Long Running”?
Before diving deeper into the challenges and solutions, it’s important to understand what we mean by “ultra-long running” workloads. It’s not as simple as just setting a specific time limit. It’s more about understanding the nuances and context.
In reality, what counts as an ultra-long running workload can vary a lot depending on the situation. For teams that usually deal with computations that complete in seconds or minutes, a job running for several hours might count as ultra-long running. On the other hand, in scientific computing or data analytics, where jobs often run for days, the threshold might be weeks or months.
A good rule of thumb is to think of a workload as ultra-long running if it lasts longer than typical workloads in your environment by one to two orders of magnitude. But there’s more to it than just runtime. We also need to think about how critical the task is and what would happen if it failed. Take a medical imaging analysis job processing a cancer patient’s data, for example. Even if it runs for just a few days, its importance and the inability to delay results might also be an important factor where mortality becomes a critical problem.
This shows that how we classify ultra-long running workloads depends not just on how long they take, but also on how long they run for, how much resource they use, and how important they are to the business or science. When a computation takes weeks to complete, or when the results are tied to critical decisions or deadlines, the consequences of Pod failure become much more serious.
Understanding Pod Mortality: The Inevitable and the Preventable
If we know what makes ultra-long running workloads tick, we can figure out why Pods fail. There are two types of Pod failure: avoidable and unavoidable. Understanding this helps us come up with ways to make these critical workloads more reliable.
Avoidable Failures: The Human Factor
The bigger category – and the one where we have the most control – is avoidable failures. These usually come from problems with the way things are set up, design mistakes, or a mismatch between the tools we use and what we need them to do. Some of the most common sources are:
- Preemption: If a higher-priority Pod takes over, it can lead to the termination of a lower-priority one.
- API-Initiated Eviction: Kubernetes might evict Pods based on API decisions, like during scaling events or policy enforcement.
- Misconfigured Resource Requests and Limits: If you set the wrong resource allocations, it can cause your Pods to be unstable or use resources in an inefficient way.
- Node Pressure: Resource exhaustion at the node level, such as CPU or memory shortages, can force the eviction of Pods. While this can’t always be avoided, it’s often preventable with the right resource management.
- Configuration issues at the workload level: Incorrect parameters or malformed input data can also cause failures during execution.
If you plan, configure and implement properly, you can avoid these failures. For ultra-long running workloads, addressing these avoidable failures can make your operations much more reliable and reduce the overhead of managing these critical computations.
Unavoidable Failures: The Forces of Nature
As we’ve already said, there are some situations where a node just can’t handle the pressure on its resources, which leads to Pods being evicted. The good news is that these issues can usually be avoided.
But some Pod failures are just out of our hands – they’re part and parcel of running distributed systems at scale. These failures include:
- Hardware Failures: From disk failures to memory errors, hardware issues can lead to Pod termination.
- Infrastructure Maintenance: Necessary system updates or hardware replacements can lead to temporary Pod disruptions.
- Network Partitions: If there are temporary or extended connectivity issues, this can isolate the Pods, which can then lead to communication failures.
- Power-Related Incidents: Anything from a short outage to a complete data centre failure can suddenly stop Pod operations.
We can’t stop these failures from happening, but we can get ready for them. The best thing to do is not try to stop them happening, but to design systems that can cope with them if they do. This is especially important for tasks that take a long time to complete, because each failure could mean days or weeks of lost work.
Strategies for Success
Selecting the Right Tool
It might seem obvious, but people often forget about choosing the right tools when they’re focused on setting up infrastructure and deployment strategies. This can be a big mistake when you’re running workloads that take days or weeks to complete on Kubernetes. The right tool isn’t just about features or performance metrics. It’s about finding technology that aligns with the unique demands of ultra-long running workloads. Let’s look at three key things that set the ideal tools apart from the rest.
Built-in State Management
Robust state management is the building block for any reliable stateful workload. You can implement checkpointing externally if you want, but tools that provide this functionality out of the box are a much better option.
A good state management system should automatically save the program’s current state at set intervals without affecting performance too much. The best tools compress these checkpoints efficiently and maintain multiple versions, so you can fall back to previous states if corruption occurs. Look for tools that make checkpointing transparent to your code while still giving you control over the frequency and storage location of checkpoints. Ideally, these should have the option to automatically pick up existing checkpoints when restarted and thus start from the latest valid checkpoint.
Resource Efficiency and Predictability
When we’re looking at workloads that extend over days or even weeks, it’s really important to ensure an efficient resource usage. Memory management is key because RAM constraints and out-of-memory events often cause Pod failures in Kubernetes. Tools that don’t play by the rules in terms of memory usage or have sudden spikes in demand can cause big problems. Teams often have to overprovision resources as a precaution. The best solution should show consistent resource use and support configurable internal memory limits that respect defined limits.
Think about how useful a tool is in practice. If it gets the job done in three days with a steady amount of resources, it’s probably more valuable than one that promises to be faster but uses more resources in a random way. If you can change how long it takes to do a task, look for tools that let you switch between being precise or being fast. This way, you can find a balance that works for you. Shorter runtimes are good, but only if they have a similar resource consumption profile and work well over time.
Kubernetes Integration
It’s best to choose tools that can handle Pod lifecycle events without any hiccups and support Kubernetes features like Pod disruption budgets. To integrate well, you need to be able to properly terminate, accurately monitor the health of the tool, and have comprehensive monitoring capabilities. The tool should have clear documentation for Kubernetes deployment and be stable for long periods of time. It’s worth noting that for workloads that run for a long time, operational reliability is often more important than raw performance.
While picking the right tool is important, even the best tool needs a proper set up to work well. In the next section, we’ll look at some key Kubernetes settings that can help keeping Pods alive and making sure everything runs smoothly. We’ll see how to set limits on resources, set up disruption budgets, and make other important changes that help create a solid environment for long-running workloads.
Kubernetes Configuration Best Practices
Good workload management in Kubernetes starts with setting the right priorities. With a well-designed priority system, you can make sure critical workloads get the resources they need while keeping the whole cluster healthy. The Kubernetes docs have lots of examples, but here’s a quick overview:
Understanding PriorityClass
PriorityClass is a cluster-wide resource that helps us understand the importance of Pods relative to other Pods. This is really important in two key scenarios:
- When the cluster is under pressure, Kubernetes uses priority to determine which Pods should be evicted first
- When scheduling, higher priority Pods get preferential treatment
Here’s an example of a high-priority configuration:
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "High priority class for critical production workloads"
preemptionPolicy: PreemptLowerPriority # Optional: explicitly state preemption behavior
Key Fields Explained:
value: Determines the relative priority (higher numbers mean higher priority)globalDefault: When true, automatically assigns this priority to Pods without a specified PriorityClasspreemptionPolicy: Controls whether Pods with this priority can preempt lower-priority Pods
Implementing Priority in Workloads
To associate a Pod with a PriorityClass, add the priorityClassName field to the Pod specification:
apiVersion: v1
kind: Pod
metadata:
name: critical-app
spec:
priorityClassName: high-priority
containers:
- name: app
image: your-app:latest
Managing Planned Disruptions with PodDisruptionBudgets
PriorityClasses are great for dealing with unexpected resource constraints, but PodDisruptionBudgets (PDBs) are perfect for managing planned maintenance activities. With PDBs, you can ensure that a specified number of Pods remain available. If you’ve got a long-running job where continuity is key, you can set up strict protection like this:
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: no-disruption-allowed
spec:
minAvailable: 100%
selector:
matchLabels:
app: critical-long-running-job
This will add a PDB to all Pods that match a specific label.
Configuring Resources and Requests
It’s easy to get confused about resource management in Kubernetes. Lots of guides say you should set requests and limits for all resources, but it’s not that simple. The best way to manage resources is to understand how different resources behave and how your workloads use them. Let’s look at how you can make better decisions about resource configuration.
The Foundation
Kubernetes uses resource requests and limits to manage how Pods use cluster resources. Requests are the guaranteed resources for a Pod, while limits are the maximum. This system helps Kubernetes make scheduling decisions and determine the order of Pod eviction when nodes are under pressure.
A Tale of Two Resources
CPU and memory behave fundamentally differently in Kubernetes, and treating them the same way can lead to suboptimal performance. Let’s explore why. CPU is a compressible resource. When a container needs more CPU than is available, it simply has to wait. Think of it like a queue at a coffee shop – if there are more customers than baristas, people wait their turn. This means we can safely overprovision CPU without causing catastrophic failures. In fact, CPU throttling often causes more problems than it solves, which is why we recommend against setting limits for most workloads.
Memory, on the other hand, tells a different story. Unlike CPU, memory can’t be compressed or throttled. When a container hits its memory limit, it’s terminated – imagine a cup that overflows when it’s too full. This abrupt behavior means we need to be especially thoughtful about how we handle memory limits.
Quotas for Long Runners
It’s important to be careful when setting resource quotas for long-running workloads. These are the marathon runners of your cluster – they need to keep up the pace over long periods and handle the odd sprint. We’ve found that setting requests at 1.5 times the expected usage provides a comfortable buffer for traffic spikes when it comes to CPU. We’ve decided not to set CPU limits for these services. This might seem a bit strange, but it actually makes the whole system run better by letting the services use the CPU when they need it, without any artificial restrictions. The same goes for memory configuration for long-runners. We set memory requests at 1.5 times the expected base usage, but here’s the key insight: we don’t set memory limits. This might make some administrators nervous, but it’s a calculated decision. Long-running workloads often have complex memory patterns, and setting limits can lead to unexpected terminations that impact Pod mortality.
Short-Running Pods: The Sprinters
Short-running Pods and batch processes have different needs. These are your cluster’s sprinters – they need resources for a short, often predictable period. For these workloads, we can be more precise with CPU requests, matching them closely to expected usage. Since the workload is predictable, we can be more confident in our resource estimates.
The way we configure memory for short-running jobs is pretty interesting. We actually set memory requests lower than we expect to need – about 80% of the expected usage. This intentional underprovision means these Pods are more likely to be evicted when memory runs tight, which is exactly what we want for short-running jobs that can be rescheduled.
Example in Practice
Consider this configuration for a long-running service:
apiVersion: v1
kind: Pod
metadata:
name: long-runner
spec:
containers:
- name: app
image: podimage
resources:
requests:
cpu: "1500m" # 1.5x expected usage
memory: "1500Mi" # 1.5x expected base memory
Notice the absence of limits – this is intentional. Now compare it to a short-running job:
apiVersion: v1
kind: Pod
metadata:
name: short-runner
spec:
containers:
- name: app
image: podimage
resources:
requests:
cpu: "500m" # Matched to expected usage
memory: "400Mi" # 80% of expected usage
limits:
memory: "512Mi" # Covers 95% of executions
The Path Forward
Effective resource management isn’t something you can just set and forget. You’ve got to keep an eye on it and make changes when you need to. Keep an eye on how your workloads are doing, check out how they’re using resources, and make any necessary changes to your settings. Keep an eye on Pod eviction events and out-of-memory kills – they’re useful signs that your resource configuration might need a little tweaking.
Just a heads-up: These guidelines are meant to be starting points, not hard-and-fast rules. Your specific workloads might have different needs, and that’s totally fine. The key is understanding the principles behind these decisions and applying them thoughtfully to your unique situation. By treating CPU and memory differently and distinguishing between long-running services and short-running jobs, you can create a more stable and efficient Kubernetes cluster that better serves your applications’ needs.
The Art of Pod Placement
Resource management is all about controlling how much of the cluster your workloads can use, while affinity rules are about where these workloads run. These placement strategies are really important for performance and reliability. Let’s look at how to use node affinity and Pod anti-affinity to create some pretty sophisticated scheduling strategies.
Node Affinity: Choosing the Right Neighborhood
Node affinity is like choosing the right neighborhood for your home. Sometimes you want to live near specific amenities, and sometimes you want to avoid certain areas altogether. In Kubernetes terms, this means selecting nodes with specific characteristics for your workloads.
Take a machine learning workload that requires GPU acceleration. Rather than hoping it lands on the right node, you can explicitly specify this requirement:
apiVersion: v1
kind: Pod
metadata:
name: highmem-pod
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: mem-type
operator: In
values:
- highmem
containers:
- name: highmem-container
image: highmem-workload
But node affinity isn’t just about the hardware. It is often used to make sure that workloads run on nodes with certain features. For example, you might want to make sure that your production workloads only run on nodes with premium storage or specific networking capabilities.
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
preference:
matchExpressions:
- key: storage-type
operator: In
values:
- premium-ssd
Notice the preferred usage instead of required here. This tells Kubernetes “try your best to place this Pod on nodes with premium storage, but if you can’t, that’s okay.” This flexibility can be crucial for maintaining service availability during cluster changes.
Pod Anti-Affinity: Maintaining Safe Distances
Node affinity helps choose where to run our Pods, while Pod anti-affinity helps keeping them apart. This is really important for high availability – you don’t want all instances of your critical service running on the same node.
Pod anti-affinity is a bit like planning store locations: you generally don’t want all your stores in the same neighborhood. Here’s how we might configure a web service to spread across nodes:
apiVersion: apps/v1
kind: Deployment
metadata:
name: long-runner
spec:
replicas: 1
template:
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- long-runner
topologyKey: "kubernetes.io/hostname"
This configuration ensures that no two Pods of your long-running workload will run on the same node. But sometimes this strict requirement can be counterproductive. For instance, during a rolling update or when scaling up rapidly, you might want to allow temporary co-location of Pods. In such cases, you can use preferred anti-affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- web-server
topologyKey: "kubernetes.io/hostname"
A Real-World Example: Computational Biology Workloads
Let’s look at how these principles play out in the real world, using computational biology as a case study. Our scenario is DNA and RNA sequence analysis, which is a great example of mixed workload management.
The Challenge
Dealing with metagenomic assemblies in Kubernetes brings a whole new set of challenges. These processes can run for weeks or even months, using over 100 CPU cores and terabytes of RAM. What makes these workloads particularly interesting is that they use resources in different ways at different times. During execution, CPU usage changes a lot between intensive computation phases and lighter processing periods, while memory consumption can go up a lot during certain stages. Adding to this complexity, these workflows often consist of long-running primary processes interwoven with shorter parallel tasks.
Our Solution in Practice
Thanks to our careful application of resource management strategies, we’ve developed a robust approach to handling these demanding workloads. We set up our long-running sequence assemblies with node anti-affinity rules and use a tiered scheduling strategy. We always schedule critical assemblies on our high-memory nodes, while less critical ones start on regular nodes and can migrate to high-memory nodes if they encounter out-of-memory events.
The proof is in the numbers. By putting a comprehensive strategy in place that combines Pod priorities, PDBs, resource quotas and strategic node placement, we’ve seen a big improvement in workflow reliability. Our long-running sequence assemblies have gone from a mere 40% success rate to over 90% – a huge improvement that has really boosted our research capabilities.
The remaining 10% of failures usually happen in two scenarios: assemblies that exceed even our high-memory node capacities, or unavoidable hardware failures. To push our success rate even higher, we’ve started experimenting with Checkpoint/Restore In Userspace (CRIU) technology.
Container Necromancy: CRIU to the Rescue
If all other strategies don’t work, we have one more tool for ultra-long-running workloads: CRIU. Think of it as a kind of “container time machine” – it can freeze a process in time, save its entire state, and bring it back to life later, right where it left off.
How CRIU Works
The beauty of CRIU is that it can capture the full state of a running process. This isn’t just about the memory contents, but everything the process needs to function: open file descriptors, network connections, and other system resources. It’s like taking a perfect snapshot of a running program, down to the smallest detail.
Our Implementation Journey
We were inspired by crik, an innovative tool showcased at KubeCon + CloudNativeCon EU 2024. Crik gave us the building blocks, and we built on them to create an experimental checkpointing system. It has two main features:
- Periodic Snapshots: These automate state preservation at configurable intervals while keeping the process running.
- Intelligent Restore Logic: This automatically detects and recovers from the latest valid checkpoint.
The result is a system that can recover long-running workloads from failures with minimal data loss and even allows Pods to be modified in between.
Understanding CRIU’s Limitations and Challenges
CRIU has some great features for keeping processes running smoothly, but it can be tricky to fit into the latest container systems. It’s important to think carefully about how it will fit into your tech stack. The current state of container runtime support is the first big hurdle we need to get over. While CRI-O and containerd 2.0 have made some progress in incorporating CRIU functionality, the implementation is still a bit fragmented. As there’s no standardized restore API across container runtimes, teams often need to develop custom solutions, which adds complexity to what might initially seem like a straightforward process.
The technical challenges of CRIU go way beyond just basic runtime support. One area is process ID management. When you’re restoring a process, CRIU has to rebuild the whole process hierarchy and make sure that the PIDs line up correctly in the container namespace. This gets really complicated in containerized environments, where you might have lots of processes running at once, each with their own set of child processes and threads that need to be preserved and restored correctly.
Terminal handling adds another layer of complexity to the CRIU puzzle. TTY restoration isn’t just about reconnecting standard input and output streams – it’s about preserving and reconstructing the entire terminal state, including window sizes, control settings, and any ongoing I/O operations. It gets even more challenging when you’re dealing with interactive apps or ones that use the terminal a lot.
Checkpoint consistency is probably the most delicate challenge of all. When CRIU takes a snapshot, it’s important to make sure that all the operations that are currently in progress are captured in a consistent state. This includes managing the I/O operations that are already in progress, handling any external resources that are needed, and making sure that the checkpoint itself is completely atomic. Imagine a situation where a process is actively writing to a database during a checkpoint. CRIU has to be really careful to make sure that the data is kept consistent and doesn’t get corrupted when the process is restored.
These limitations don’t mean CRIU isn’t useful – quite the opposite! However, this does mean that teams need to plan their CRIU implementation carefully and understand the challenges involved. It’s like performing delicate surgery: you need precision, expertise and a thorough understanding of the underlying system architecture.
We do recommend using CRIU only as a last resort and suggest using built-in persistence before integrating it into your containers.
Summary and Outlook
Kubernetes has come a long way from being a platform for stateless microservices to one that can handle workloads that run for a very long time. This is a big change in cloud-native computing. This article shows that the issue of Pod mortality in Kubernetes isn’t a problem. It’s just something to think about when planning and implementing your solution.
By taking a holistic approach that includes choosing the right tools, managing resources in a smart way, and placing Pods in the best spots, companies can get amazing reliability for workloads that run for days or weeks. The real-world example from computational biology is a great illustration of Kubernetes’ ability to reliably handle even the most demanding long-running workloads. It shows how success rates improved from 40% to over 90% for complex DNA and RNA sequence analysis.
The key to success isn’t fighting Pod mortality, it’s accepting it and planning for it. If teams understand both avoidable and unavoidable failures, they can put in place effective strategies, from proper priority configuration to intelligent resource allocation. Our article goes into a lot of detail about CPU and memory management. It shows that taking a more nuanced approach – like avoiding CPU limits while carefully managing memory – can get better results than using a one-size-fits-all solution.
Looking ahead, we can expect to see new developments in this area. We can probably expect container runtimes to evolve to better support checkpoint/restore capabilities, which would make CRIU integration more seamless. As more and more people start using Kubernetes in scientific computing and other fields that require ultra-long running workloads, we’ll probably see some new innovations in workload management and reliability features. And as edge computing continues to grow, these strategies for managing long-running workloads will become increasingly relevant. Thus, lessons from managing these demanding workloads could benefit the broader Kubernetes ecosystem, enhancing reliability, manageability, and efficiency for all users.